The Importance of Hyperparameter Optimization in Machine Learning Models Applied to Mining
In recent years, the use of Machine Learning (ML) in mining has grown significantly, particularly in applications related to grade prediction, metallurgical recovery, geological classification, and geometallurgical variables such as hardness, energy consumption, and throughput.
However, one of the most important — and at the same time most underestimated — aspects in the development of predictive models is hyperparameter optimization.
It is relatively common to find studies comparing algorithms using only default parameters. In many cases, this leads to incorrect conclusions regarding the true performance of the models. An algorithm that initially appears “poor” may substantially outperform another if its hyperparameters are properly tuned.
In mining, where datasets are often limited, expensive, and spatially correlated, proper hyperparameter optimization can represent the difference between a robust model and one that is operationally unusable.
The objective of this article is to review:
- What hyperparameters are?
- Why are they important?
- How do they affect ML model performance?
- Existing optimization methodologies
- Examples applied to geometallurgical variables
- Risks associated with overfitting
- Practical recommendations for mining
What Are Hyperparameters?
In simple terms, hyperparameters are external configurations that control the behaviour of a Machine Learning algorithm.
Unlike the model’s internal parameters, which are learned automatically during training, hyperparameters must be defined by the user before training begins.
For example:
Random Forest
Some typical hyperparameters include:
- Number of trees
- Maximum depth
- Minimum number of samples
- Number of variables evaluated at each node
XGBoost
Among the most relevant hyperparameters are:
- Learning rate
- Number of estimators
- Depth
- Regularisation
- Subsampling
- Column sampling
Neural Networks
In neural networks, hyperparameters include:
- Number of layers
- Number of neurons
- Learning rate
- Batch size
- Activation functions
- Dropout
- Optimiser
All these parameters directly affect predictive capability, stability, training time, generalization, and the risk of overfitting.
Why Are Hyperparameters So Important?
Two models using exactly the same algorithm may produce completely different results depending on how their hyperparameters are configured.
For example:
- An overly complex model may memorize noise
- An overly simple model may fail to capture real patterns
- An incorrect learning rate may prevent convergence
- Too many trees may increase overfitting
- Too few trees may generate underfitting
In mining, this is especially relevant due to:
- relatively small datasets
- high spatial variability
- geological noise
- presence of outliers
- complex domains
- highly skewed distributions
Poor tuning can lead to models that appear statistically attractive during training, yet are entirely inconsistent when applied to new areas of the deposit.
Overfitting and Underfitting
One of the main goals of optimisation is to find the correct balance between predictive capability and generalisation.
Underfitting
Underfitting occurs when the model is too simple to capture the true complexity of the data.
Consequences include:
- Poor performance
- High bias
- Inability to model non-linear relationships
Examples include:
- Trees that are too shallow
- Too few estimators
- Excessive regularisation
Overfitting
Overfitting occurs when the model learns noise and specific characteristics of the training dataset. In mining, this is particularly dangerous due to spatial autocorrelation.
Consequences include:
- artificially high metrics
- poor validation performance
- low extrapolation capability
In many cases, a model appears extremely accurate simply because the training and validation samples are spatially close to one another.
Example of Hyperparameter Optimization
In this example, a Random Forest Regressor model was developed to predict the grade of a target variable using a set of geochemical variables.
To maximize the model’s predictive capability, Optuna was used — a hyperparameter optimization library based on intelligent search techniques that efficiently explore the solution space. Unlike traditional approaches such as Grid Search or Random Search, Optuna employs sequential optimization algorithms that learn from previous evaluations in order to focus the search on the most promising regions. During the process, each hyperparameter combination was evaluated through cross-validation using the coefficient of determination (R²) as the objective metric.
Figure 1 presents the validation curves obtained for the main hyperparameters of the optimized model. These curves illustrate how Random Forest performance varies as model complexity changes. In general, very low levels of complexity lead to underfitting, where the model is unable to adequately capture grade variability, while excessively complex configurations tend to increase the risk of overfitting, reducing the model’s ability to generalize to unseen data. The values selected by Optuna correspond to the region where validation performance reaches its maximum or remains stable.
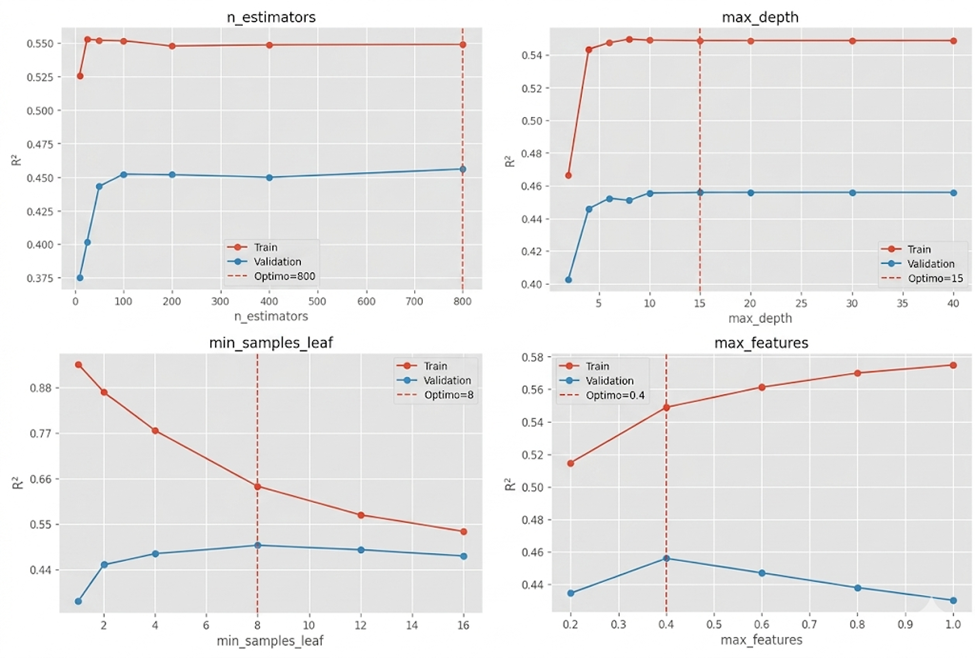
The results clearly demonstrate the benefits of hyperparameter optimization. The baseline Random Forest model achieved an R² of 0.454, while the optimized model increased this value to 0.696, representing a relative improvement of 53.25% in explanatory capability. Likewise, RMSE decreased by 25.35%, and MAE was reduced by 16.54%, demonstrating a significant improvement in prediction accuracy.
These results show that systematic hyperparameter optimization constitutes a fundamental stage in the development of predictive models for grade estimation, allowing substantially better performance to be extracted even from already well-established algorithms such as Random Forest.
Final Reflection
Hyperparameter optimization represents one of the most important aspects of Machine Learning applied to mining. In many cases, the difference between a useful model and an unusable one does not depend on the selected algorithm, but rather on how it was tuned.
However, optimization should not be understood solely as a mathematical problem. In mining, models must respect:
- geological consistency
- spatial continuity
- domains
- support
- operational behaviour
The real challenge is not to build the model with the highest R², but rather to develop robust, interpretable models capable of generalizing correctly to new areas of the deposit.
The combination of geological knowledge, geostatistics, and intelligent Machine Learning optimisation currently represents one of the most promising areas for the development of advanced predictive models.
This raises an increasingly relevant question: how many models considered “poor” in mining actually failed because of the algorithm… and how many simply because of an inadequate optimization process?


